.webp)
Free MLOps Course for Data Scientists: Day 5 - Data Drift and Model Monitoring. CI/CD Pipelines.
A practical guide to data drift monitoring and CI/CD for production ML systems: how to detect model degradation, data drift, and concept drift, and how to ship changes safely with CI/CD.

Welcome to Day 5 of my 5-day MLOps Course for Data Scientists.
Day 1 - Production ML System Components
Day 2 - Databases and Data Processing
Day 3 - Machine Learning Pipelines
Day 4 - Feature Store, Model Registry and Experiment Tracking
So far in this course, we have covered:
- Detailed overview of ML System components
- Databases and Data Processing
- Machine Learning Pipelines
- Feature Store, Model Registry and Experiment Tracking
Today, we get to the two things that keep a deployed model from quietly failing on you.
The first is data drift and model monitoring. Usually, a model doesn't stay accurate forever. The data it sees in production drifts away from what it was trained on.
The relationships it learned change over time, and its predictions gradually stop reflecting reality.
Without proper monitoring, none of these problems are visible until something downstream breaks.
The second component is CI/CD pipelines, which is the way of how you ship changes to a production ML system reliably and without rebuilding everything by hand every time.
1. Data and Model Monitoring
Deploying a model is not the end of the project, it's actually the start of its most critical phase.
In production, the conditions the model was trained under rarely stay stable. Customer behavior evolves, sensors change, seasonality kicks in, fraudsters adapt, markets shift. The model that worked yesterday quietly stops working today, and without monitoring, no one notices until a business metric largely degrades.
There are the main scenarios to watch. Let’s check the figure below.
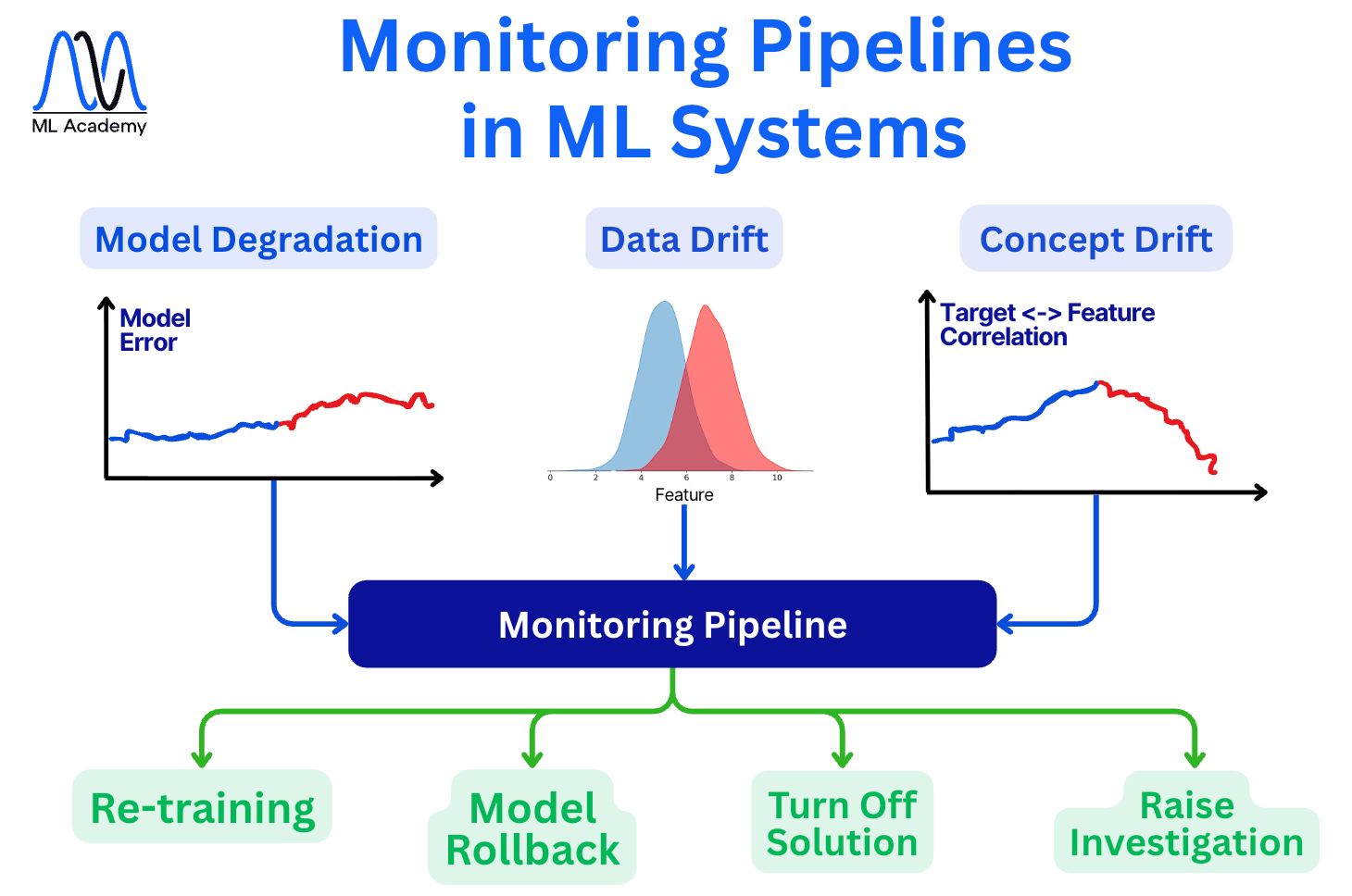
Now, let’s break down each scenario.
1. Model Degradation
Here, model error is tracked over time. This is the symptom that matters most: an increasing error means the model is getting worse, whatever the cause.
However, this is usually the consequence of two other problems.
2. Data Drift
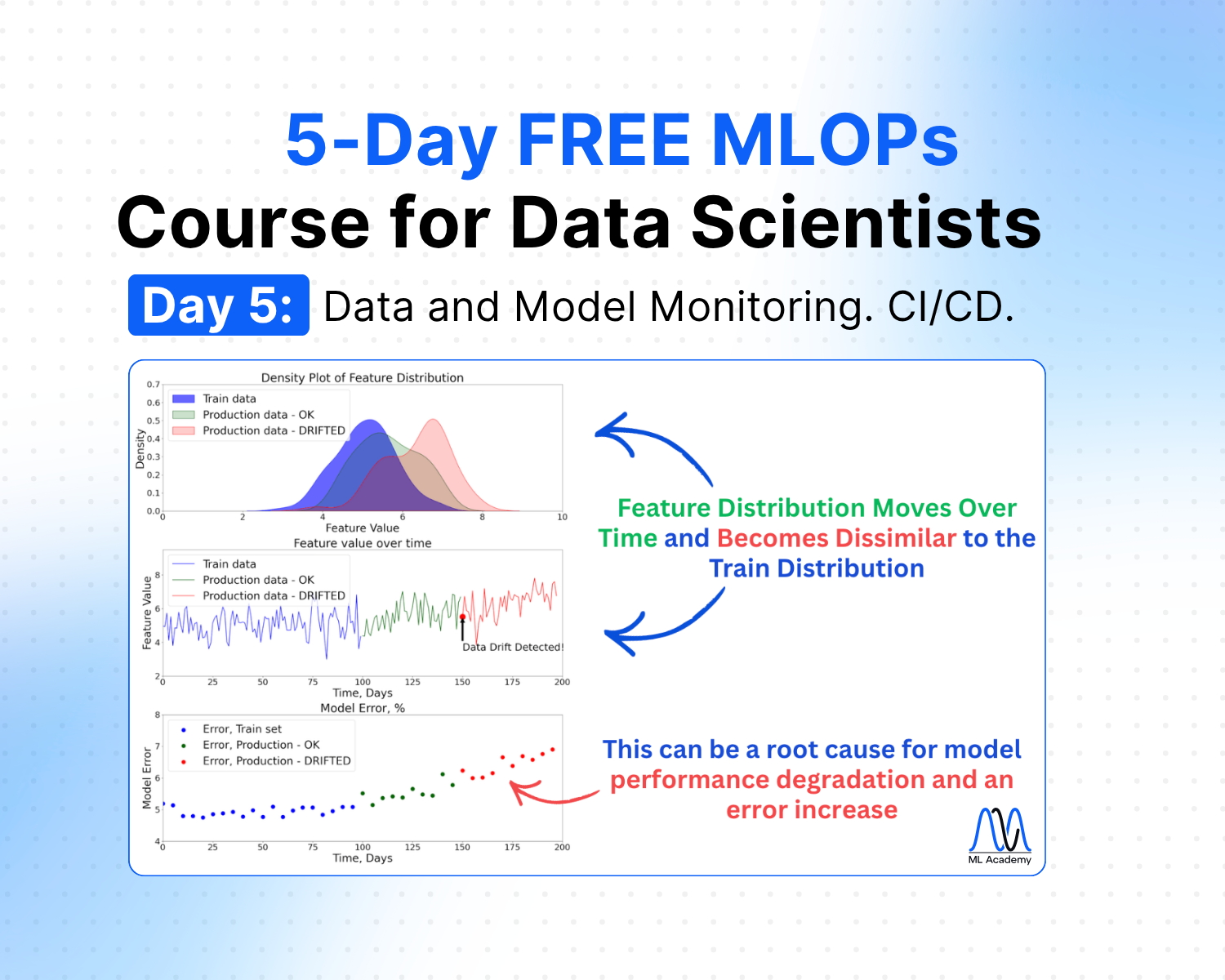
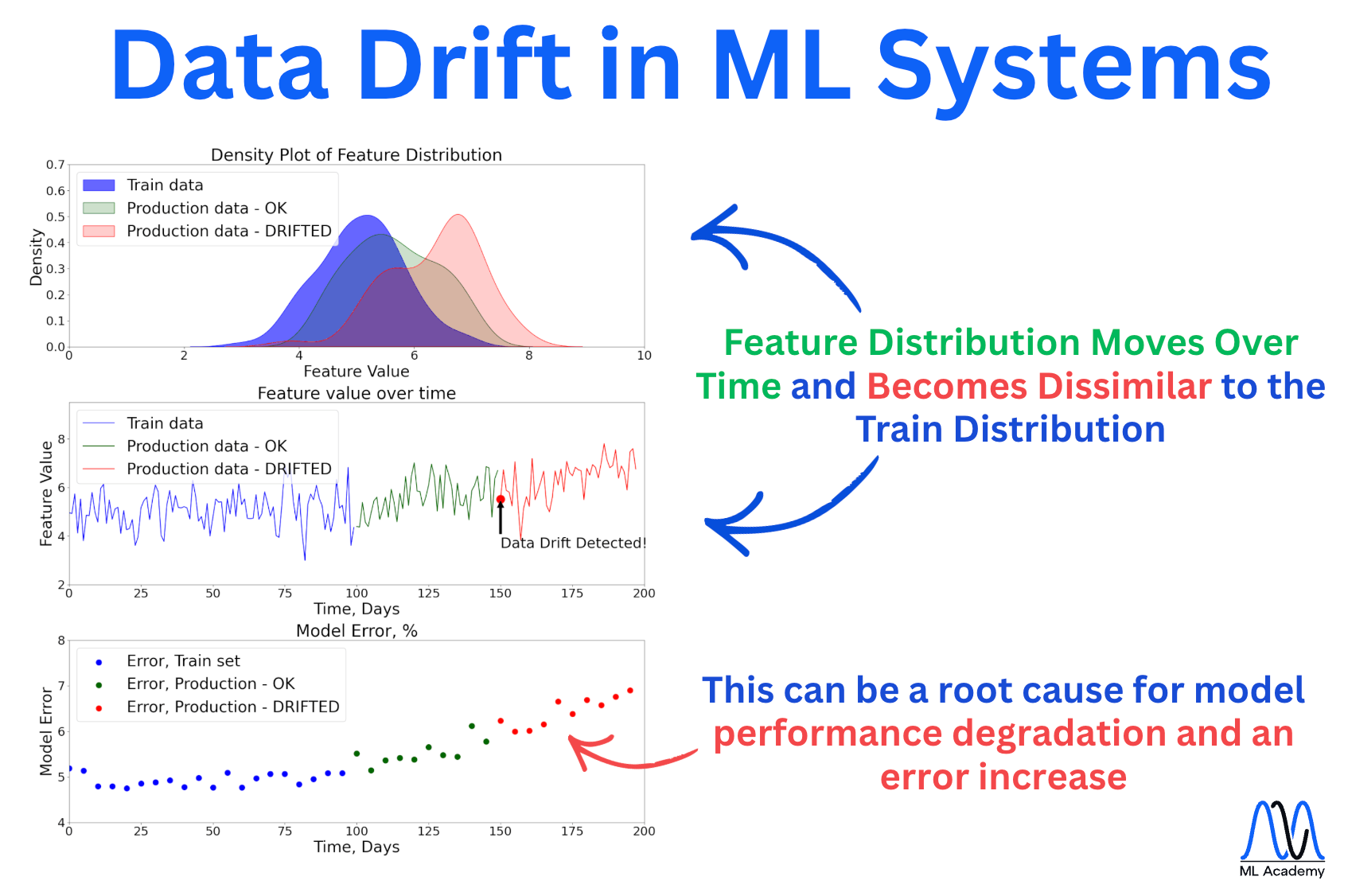
In this case, the distribution of the input features shifts away from what the model was trained on (the two curves pulling apart in the figure).
Here’s an example of how data drift can cause model performance degradation.
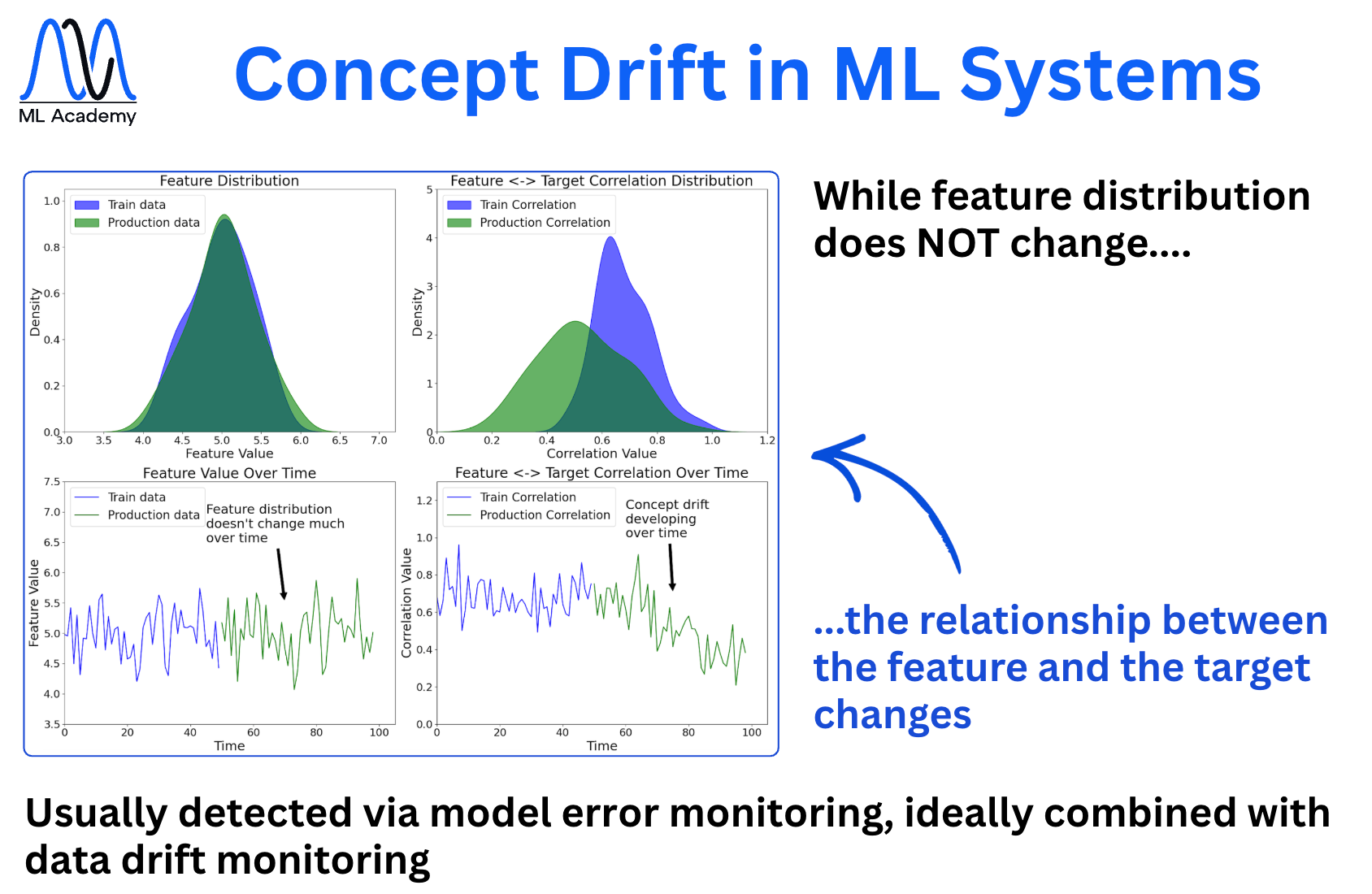
3. Concept Drift
Concept Drift happens when the relationship between features and the target changes. Notice in the figure below that the target-feature correlation rises and then falls. In this case, the feature distributions can look fine while the link between features and the target breaks.
How to Detect Data Drift
There are two main types of data drift: univariate and multivariate.
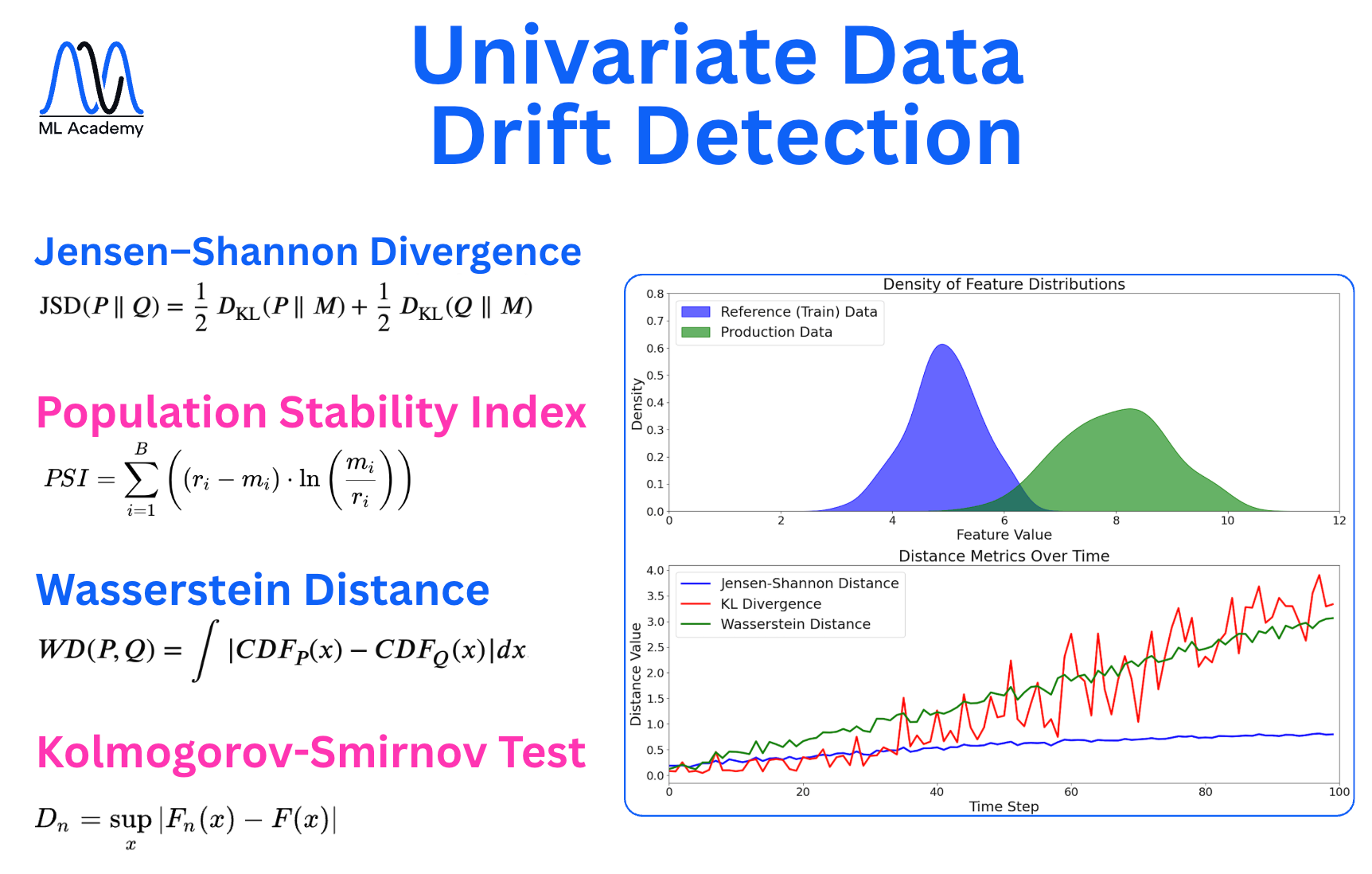
Univariate data drift is when a single feature drifts. In this case, the methods to detect the drift check each feature independently. The most commonly used ones are the Kolmogorov-Smirnov test, Population Stability Index, Jensen-Shannon Divergence, and Wasserstein Distance.
Here’s a breakdown of some of the methods (+ KL divergence on the plot) and their behavior during the data drift over time.
Multivariate methods are needed when the overall distribution shifts, but no single feature shows it clearly. In this case, univariate methods might miss the drift entirely. Let's look at the figure below.
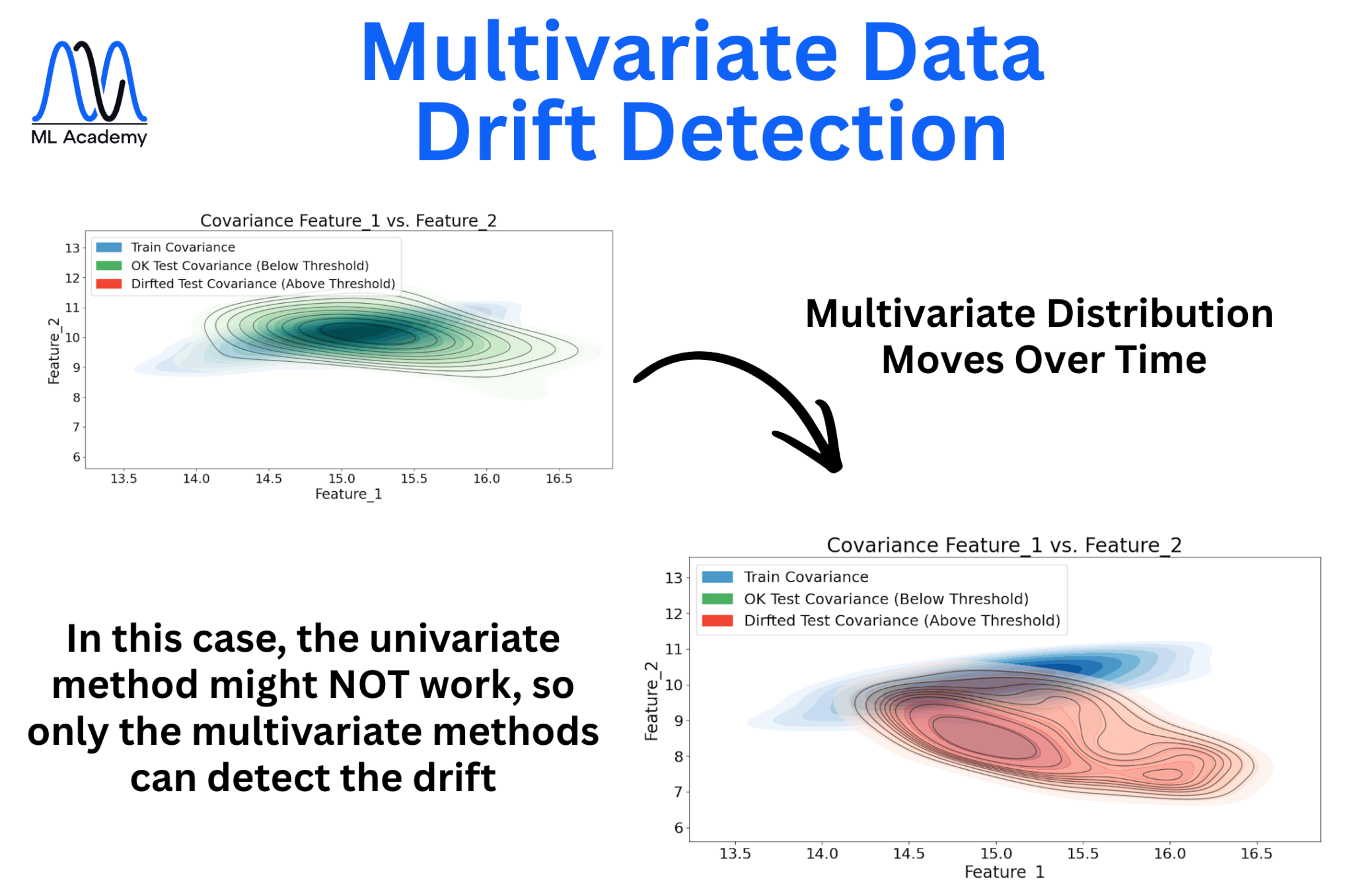
There are several methods to detect a multivariate data drift:
- PCA Reconstruction Error
- Autoencoder Reconstruction Error
- Domain Classifier
Actions to take in case of data drift
Once the Monitoring Pipeline detects a problem, it triggers one of four responses (the green boxes in the figure):
1. Re-training — retrain the model on fresh data. This is the most common response.
2. Model Rollback — revert to the previous @champion version if the current one has gone bad. That model can also work poorly, but a check is worth it.
3. Turn Off Solution — disable the model entirely until the problem is fixed. This is required to avoid wrong decision making that can strongly affect the business.
4. Raise Investigation — alert a human to dig into the root cause when an automated fix isn't appropriate.
2. Continuous Integration / Continuous Delivery (CI/CD)
While monitoring keeps deployed models reliable, CI/CD lets you ship changes from your local environment to the production environment quickly and safely, rather than by hand.
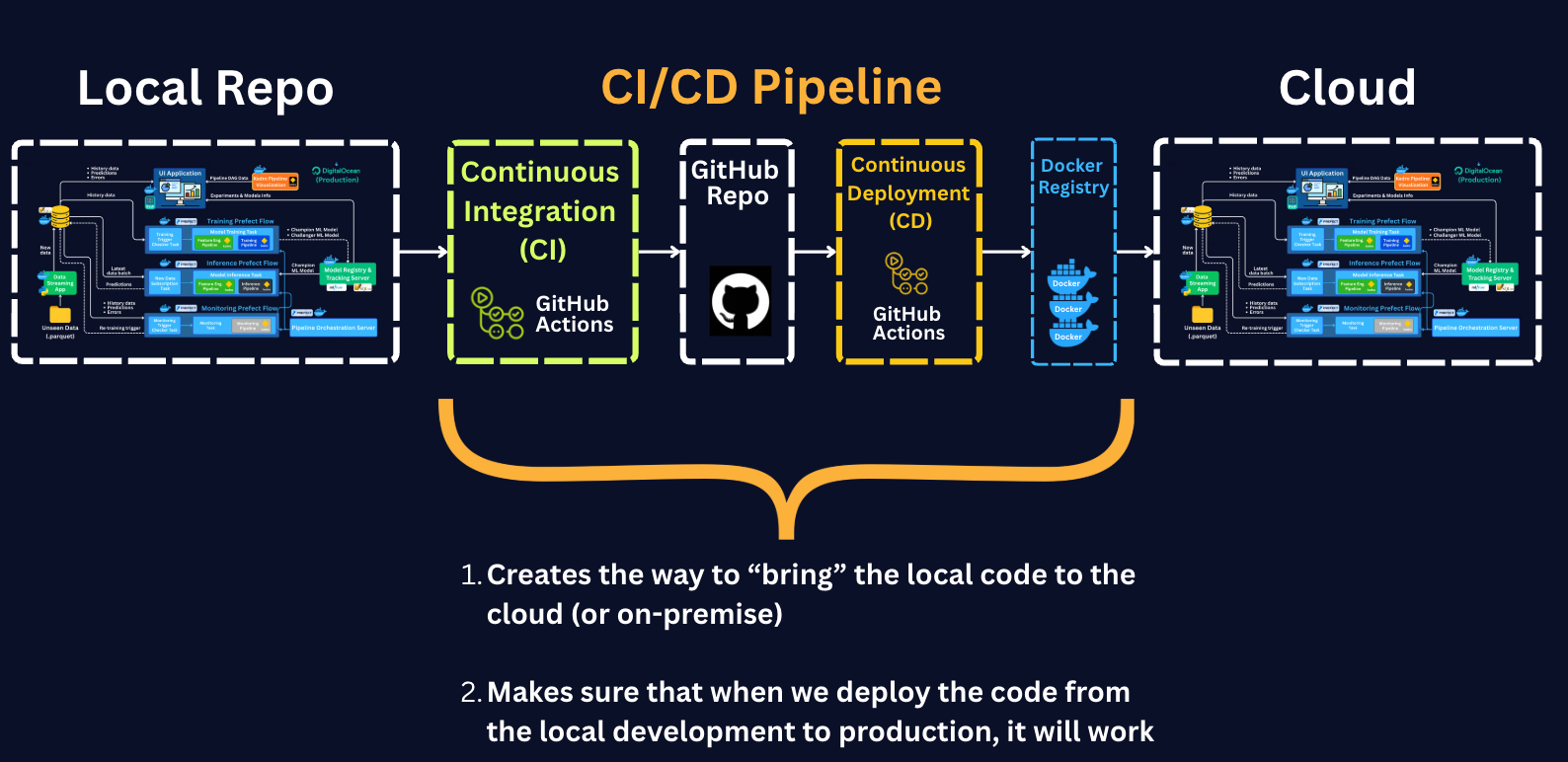
Let’s break each pipeline down separately.
Continuous Integration (CI)
CI automatically checks your project every time code is pushed. In an ML project, a typical CI pipeline (for example, built with GitHub Actions) runs:
- Code quality tests — linting and auto-formatting (Ruff), type checking (Ty), enforced through pre-commit hooks
- Code Tests — unit tests (e.g., with Pytest) on individual pipeline nodes, integration tests on the feature engineering and training pipelines, plus reproducibility checks
- Docker builds — build and test the Docker images so the deployment environment stays consistent
The point of CI is to catch errors before they reach production and to enforce the same standards across the whole team. This matters more in ML than in normal software, because ML code can break silently, for example, a change to preprocessing or feature logic won't throw an error, but it might affect the final model predictions.
Here’s the overview of how CI pipeline works.

Let’s break down each step.
Every time a developer pushes code to the repository, that push acts as a trigger. A trigger is an event that tells the CI system to start. The CI system then kicks off a pipeline, which is just a sequence of jobs that run in order.
A job is a process that runs a group of tasks inside a temporary virtual machine called a runner. The runner spins up fresh for each job and is destroyed once the job finishes, which means every run starts from a clean state with no leftover artifacts from previous runs.
Each job is made up of steps which are individual tasks that execute one after another. The build job, for example, might have a step to check out the repository, a step to set up Docker, and a step to build the Docker image.
In a typical ML project, the CI pipeline runs three jobs in sequence. First, the lint step runs which checks code formatting and style using tools like Ruff.
Second, the test step runs unit tests on individual functions, integration tests on the feature engineering and training pipelines, and reproducibility checks.
Third, the build step builds the Docker images that will be deployed to production.
Each job has to pass before the next one starts. If lint fails, the test never runs. If the test fails, build never runs, and nothing reaches production.
The results, logs, and artifacts from each job are collected and stored, so you can always inspect exactly what passed or failed and why.
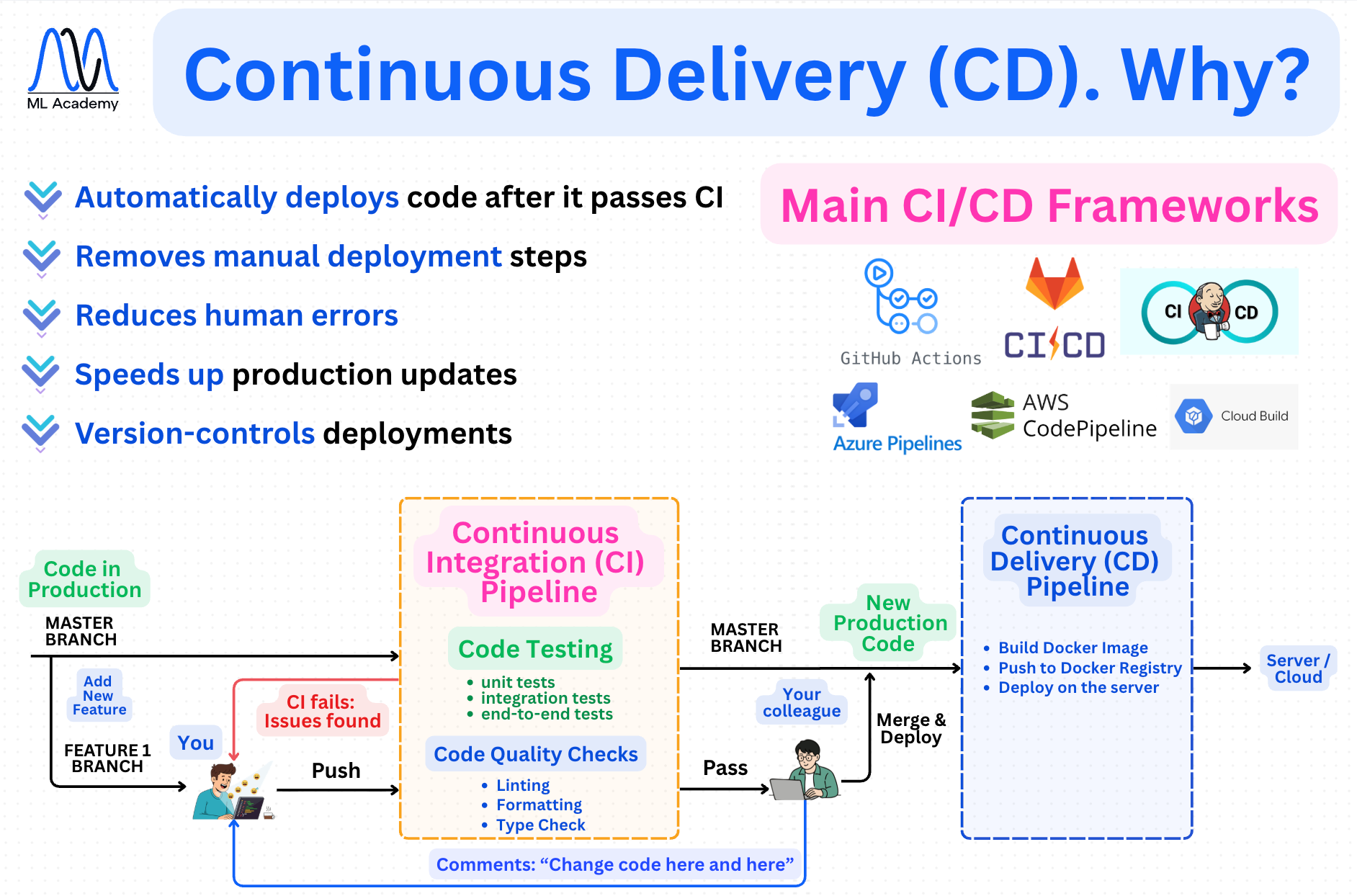
Continuous Delivery (Deployment) (CD)
CD takes what passed CI and gets it running in production. This usually means that the code is pushed to the GitHub repo, GitHub Actions builds Docker images and pushes them to a Docker registry, and the containers are deployed to the production environment.
Here’s a breakdown of why to run a CF pipeline, how it’s connected to a CI pipeline and what are the main steps of it.
CI/CD Tools
There are three tools that cover most of what teams use for CI/CD in practice.
GitHub Actions is the most common one you'll encounter. It's built directly into GitHub, so there's no separate service to set up or connect. You define your pipeline in a YAML file inside the repository, push code, and the pipeline runs automatically. For most ML projects hosted on GitHub, it's the default choice.
GitLab CI works the same way but lives inside GitLab. If your team uses GitLab for version control, the CI system is already there. The configuration is also YAML-based and follows the same trigger-job-step structure. GitLab CI is common in enterprise environments where GitLab is the preferred platform.
Jenkins is the oldest of the three and the most flexible. It's self-hosted, which means you run it on your own infrastructure rather than relying on a cloud provider. That gives you full control over the environment, the runners, and the configuration, but it also means more maintenance overhead. Jenkins is still widely used in large organizations with complex pipelines or strict data residency requirements, but for most modern ML projects starting from scratch, GitHub Actions or GitLab CI is the simpler path.
Summary
Let's recap what we covered today.
The first topic was data and model monitoring. In production, three things can go wrong: model degradation, data drift, and concept drift. Model degradation is the symptom you track directly, and data drift and concept drift are usually the underlying causes.
To detect drift, you have two families of methods. Univariate methods like the Kolmogorov-Smirnov test and Population Stability Index check each feature independently.
Multivariate methods like Domain Classifier and Autoencoder Reconstruction Error are needed when the overall distribution shifts but no single feature shows it clearly.
Once a problem is detected, the monitoring pipeline triggers one of four responses: retraining the model on fresh data, rolling back to the previous champion, turning off the solution entirely, or raising an investigation for a human to dig into.
The second topic was CI/CD. CI automatically validates every code change by running linting, tests, and Docker builds in sequence before anything reaches production. CD takes what passed CI and deploys it to the production environment as containers.
Together, they make it possible to ship changes quickly without rebuilding everything by hand or risking the "works on my machine" problem in production. The main tools for this are GitHub Actions, GitLab CI, and Jenkins, each suited to different team setups and infrastructure preferences.
MLOps Course Summary and What’s Next
Five days ago, you had a clear picture of what happens inside a Jupyter notebook.
Now you have a clear picture of what happens around it.
You started with the 10 components that make up a production ML system and learned how they connect.
You went through data storage and processing, understanding why the choice between batch and streaming isn't a technical preference but a business requirement.
You walked through how ML pipelines are structured, what each one is responsible for, and how features, training, and inference fit together.
You learned how experiment tracking and the model registry give your models a traceable path from experiment to production.
And today, you saw how monitoring keeps a deployed model honest over time, and how CI/CD makes shipping changes something you can do confidently instead of something you avoid.
Most Data Scientists spend years picking this up piece by piece. You now have it in one place.
Related Articles



Free MLOps Course for Data Scientists: Day 2 - Databases and Data Processing
A five-part guide to data storage and processing for production ML systems: relational, column-oriented, vector, and key-value databases, plus streaming and batch processing explained for Data Scientists.
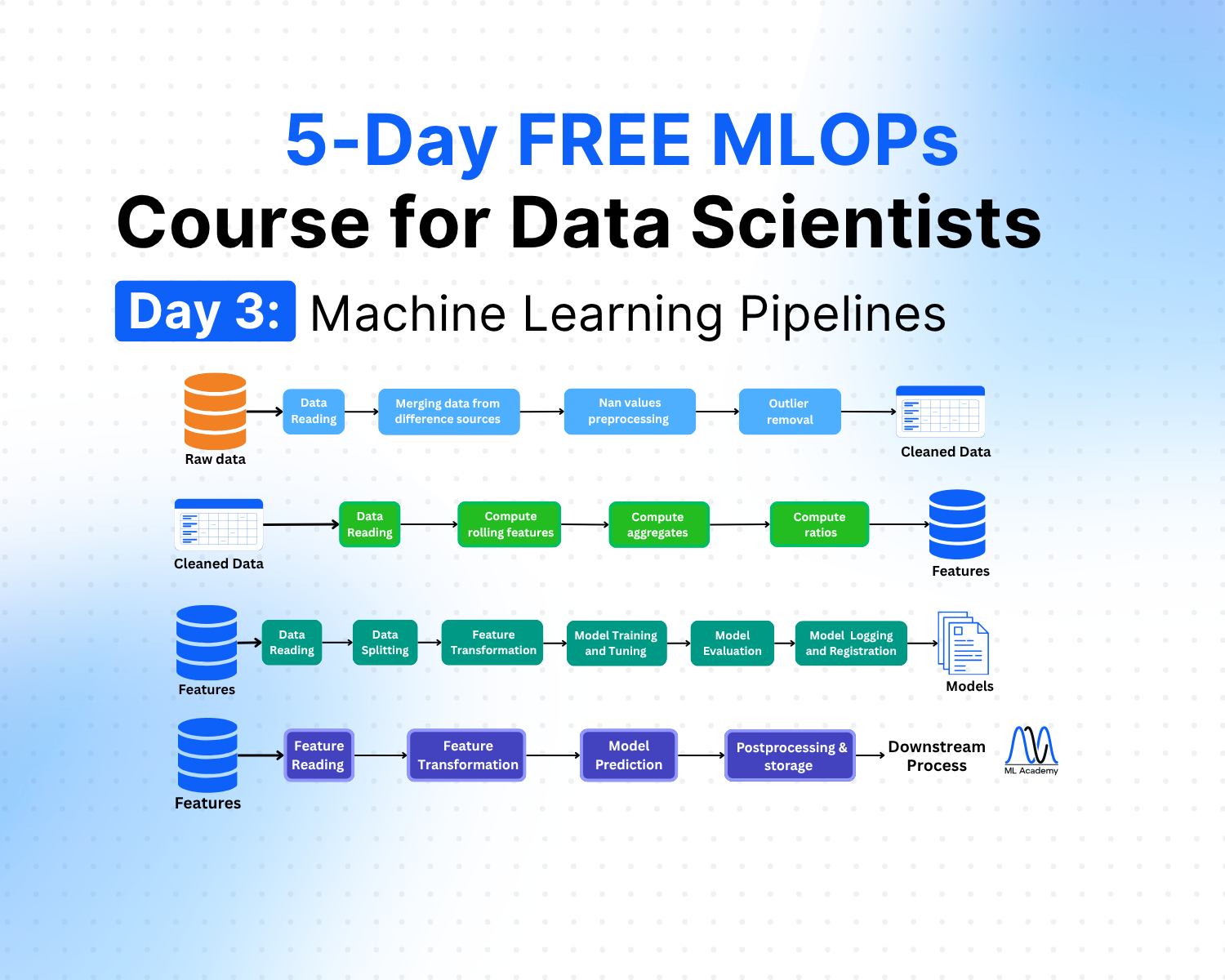
Free MLOps Course for Data Scientists: Day 3 - Machine Learning Pipelines
A practical guide to ML pipelines for Data Scientists: preprocessing, feature engineering, training, and inference pipelines explained with Python code examples and implementation best practices.
Ready to transform your ML career?
Join ML Academy and access free ML Courses, weekly hands-on guides & ML Community