Machine Learning Solutions - Architecture and Main Components
Sep 29, 2025
Introduction to Machine Learning Solution Components & Architecture
Building a machine learning model in a Jupyter notebook and deploying it to production are two entirely different challenges. While your experimental model might achieve impressive accuracy on test data, production ML systems require a comprehensive architecture that handles data ingestion, feature engineering, model training, deployment, monitoring, and continuous maintenance.
The reality is that the actual machine learning code represents only a small fraction of a production ML system. The supporting infrastructure—data pipelines, feature stores, model registries, monitoring systems, and deployment automation—comprises the majority of the system's complexity.
Production ML systems face unique challenges that traditional software systems don't encounter:
Data Distribution Changes
Unlike conventional software with predictable inputs, ML systems must adapt to evolving data distributions. User behavior changes, market conditions shift, and external data sources evolve continuously.
Model Performance Degradation
Traditional software failures are typically binary—the system either works or crashes. ML models degrade gradually and often imperceptibly, requiring sophisticated monitoring to detect performance deterioration.
Complex Dependencies
ML systems create intricate webs of dependencies between data sources, feature engineering logic, model artifacts, and serving infrastructure. Changes in one component can have unexpected effects throughout the system.
Reproducibility Requirements
ML development is inherently experimental, requiring systematic tracking of experiments, model versions, and environmental configurations to ensure reproducibility and enable debugging.
To be a successful Data Scientist in the current market, you need to understand what goes into production ML systems and how to properly design them.
What You'll Learn in This Guide
This guide covers the 10 essential components of production ML systems and how they work together:
- Architecture patterns and design principles for reliable ML systems
- Core components from data storage to monitoring, with practical examples
- Tool selection guidance for different ML application types
- Real-world challenges like data drift, scaling, and continuous deployment
By the end, you'll have a solid understanding of what goes into production ML systems and how the pieces fit together.
Why Data Scientists Need to Understand ML System Architecture
The role of a data scientist has evolved significantly. While a few years ago, Data Scientists could focus primarily on model development and experimentation.
Today's Data Scientists are expected to understand the full lifecycle of ML systems and contribute to production deployments.
Look at the modern Data Scientist skill landscape associated with different levels.

Understanding ML system architecture is crucial for modern Data Scientists for several reasons:
Career Advancement.
Companies increasingly value Data Scientists who can bridge the gap between experimentation and production. Understanding system architecture makes you a more versatile and valuable team member.
Better Model Design.
When you understand how your model will be deployed and used, you make better design decisions during development. You consider inference latency, memory constraints, and data availability from the start.
Debugging and Troubleshooting.
Production ML systems fail in complex ways. Understanding the architecture helps you diagnose whether issues stem from data quality, model performance, infrastructure problems, or integration failures.
End-to-End Thinking.
Modern Data Science requires thinking beyond model accuracy. You need to consider data pipelines, feature engineering, monitoring, and maintenance as integral parts of the solution.
Technical Leadership.
Senior Data Scientists are often expected to make architectural decisions and guide technical strategy. This requires understanding how different components interact and scale.
The days of "throwing models over the wall" to engineering teams are over. Today's successful data scientists understand that model development is just one part of a larger system, and they actively contribute to designing and maintaining that system.

Machine Learning Solution Architecture
A model Machine Learning Solution is a complicated software that includes many components. Usually, these components require continuous development as the system that ML Solution models also continuously changes.
An architecture of a typical ML solution includes traditional software components, such as data storage or CI/CD pipelines, as well as industry-specific components like training and inference pipelines, feature stores, or a model registry.
Despite the ML solution architecture heavily depends on the business application, e.g., fraud detection or recommendation systems, we usually can distinguish 10 common components.
- Data Storage
- Data Processing (Streaming / Batch)
- Preprocessing & Feature Engineering Pipelines
- Feature Store
- Training Pipeline
- Inference Pipeline
- Model Registry
- Experiment Tracking
- Data & Model Monitoring
- CI/CD for ML (MLOps Automation)
Each system has its own purpose. This is described in more detail in the next section.
Before we dive into each component, let us see the general architecture of a typical ML Solution and how these components are connected.

At first, this diagram might seem a bit overwhelming, and it is. That is why we go into each component in more detail to make a complete sense of this diagram.
In the next section, we will build a couple of different representations of this diagram. We do this intentionally to help you understand the idea, not memorize a picture. Take your time to compare the diagrams and combine them with the components' descriptions.
At the end of the article, I hope you get a good understanding of each component and how these components interact with each other.
ML Solutions Design Principles
Before examining specific components, it's important to understand the core principles that guide successful ML system architecture:
Modularity and Separation of Concerns
Each component should have a clearly defined responsibility. Data ingestion, feature engineering, model training, and inference should be loosely coupled and independently deployable.
Reproducibility and Versioning
Every aspect of the ML pipeline must be versioned and reproducible—from data snapshots to model artifacts to infrastructure configurations.
Observability and Monitoring
ML systems require comprehensive observability beyond traditional application metrics, including data drift detection, model performance monitoring, and prediction quality assessment.
Gradual Deployment Strategies
New models should be deployed through progressive strategies—shadow deployments, canary releases, and A/B testing—to minimize risk and enable rapid rollback if issues arise.
Now, let's dive into ML Solution Components in model detail
ML Solution Components - Detailed Description
1. Data Storage.
This is the place where everything starts. No ML solution can be built without data. The choice of storage technology significantly impacts both the speed of your ML system and how easy it is to maintain over time. Different types of ML applications have different storage requirements based on their data characteristics and performance needs.
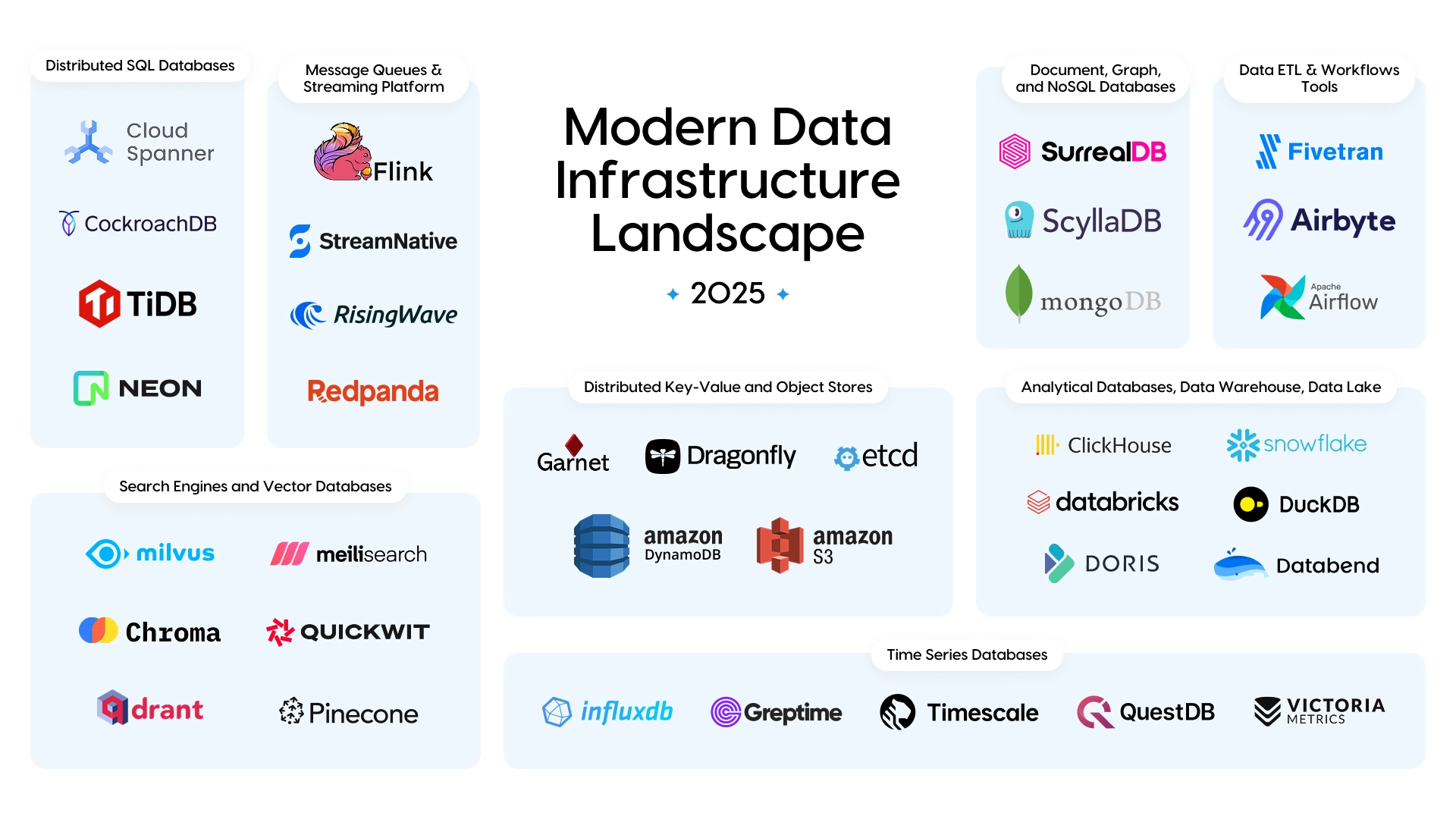
Modern Database landscape (Source)
Here is a short description of database types for the most common data types and applications.
Tabular data
For tabular data applications like fraud detection or customer churn prediction, you typically work with structured data that fits well in traditional databases. SQL-based data warehouses like Snowflake or BigQuery are popular because they allow fast queries using familiar SQL syntax.
These systems are optimized for analytical workloads and can handle billions of rows efficiently. The main advantage is that data scientists can easily explore and analyze the data, while data engineers can maintain consistent schemas and data quality checks
Time Series data
Time series applications such as IoT sensor monitoring or financial trading systems need specialized storage that can handle high-volume, continuous data streams. Time series databases like InfluxDB or TimescaleDB are designed specifically for this purpose.
They can ingest millions of data points per second while providing fast queries for specific time ranges. Traditional databases struggle with time series data because they weren't designed for the continuous append-only nature of temporal data.
Large Language Model (LLM)
LLM applications present unique storage challenges because they work with massive amounts of text data that needs to be processed and tokenized. The raw text is typically stored in distributed file systems like S3 or HDFS because these can handle petabytes of data cost-effectively. However, the processed and tokenized data is often stored in formats like Parquet that enable faster reading during training. Many LLM applications also use specialized vector databases to store embeddings for retrieval-augmented generation (RAG) systems.
Important factors to consider
Speed
Speed considerations vary significantly by application type. Real-time applications like fraud detection need storage systems that can serve data within milliseconds, often requiring in-memory databases or caching layers.
Batch training applications can tolerate higher latency but need high throughput to process large datasets efficiently. Streaming applications need storage that can handle both high write rates and fast reads simultaneously.
Scalability
Scalability is another critical factor that affects storage choice. Your ML system needs to handle growing data volumes, increasing numbers of users, and more frequent model updates. Traditional relational databases might work fine for initial prototypes but can become bottlenecks when you need to process terabytes of data daily.
Cloud-native storage solutions like data lakes and distributed databases are designed to scale horizontally—you can add more storage capacity and processing power by adding more machines rather than upgrading existing hardware.
2. Data Processing (Streaming / Batch)
This part of ML Solutions is responsible for processing the data and directing it to the right process. There are 2 main types of data processing in ML applications - streaming and batch. Below you can see a schematic representation of these different approaches with a detailed description later on.

Streaming Data Processing
In the case of streaming, data is processed and served within milliseconds.
A typical example of it is fraud detection systems, where the ML system must identify if the transaction is fraudulent or not and prevent catastrophic consequences.
The tools that are typically used for these:
Message Brokers: Apache Kafka, Amazon Kinesis
Stream Processing: Apache Flink, Kafka Streams, Spark Streaming
Batch Data Processing
In the case of batch data processing, data is collected over a period of time and then processed and served in bulk. Latency is not as critical as in streaming, since results are expected within minutes or hours rather than milliseconds.
A typical example is demand forecasting in retail, where the system processes historical sales data every night to generate predictions for the upcoming week. Accuracy and scalability matter more than immediate response.
The tools that are typically used for these:
-
Batch Orchestration / Scheduling: Apache Airflow, Prefect, Luigi
-
Distributed Processing: Apache Spark, Hadoop
3. Preprocessing & Feature Engineering Pipelines
ML Pipelines in general are a sequence of steps to transform data or to perform some actions, for instance, model training.
A Preprocessing Pipeline is the one where raw data is transformed into a clean and consistent format before it can be used in feature engineering. Without preprocessing, models risk learning from noise, inconsistencies, or irrelevant signals.
Task Examples:
-
Handling missing values, outliers, and duplicates
-
Normalizing or scaling numerical data
-
Encoding categorical variables
A Feature Engineering Pipeline is responsible for creating features that are then used by a Machine Learning model
Task Examples:
-
Deriving new features (e.g., ratios, rolling averages, time lags)
-
Extracting domain-specific attributes (e.g., distance between GPS coordinates)
-
Representing complex data (e.g., embeddings for text, image augmentation for vision tasks)
Often, Preprocessing and Feature Engineering Pipelines are combined into one. However, in case of messy data, it's a good idea to split them because they focus on different tasks and combining them into one can create hard-to-read and maintain code.
4. Feature Store
The feature store is the central hub for managing ML features. It solves one of the biggest problems in production ML systems — ensuring that the same features used during model training are consistently available for inference. It acts as a bridge between raw/preprocessed data and the ML models, enabling feature standardization, reusability, and governance. In the animation below, you can see where the Featore Store is placed among ML Solution components.

Key benefits:
-
Consistency: Guarantees that features are computed the same way during training and serving (no training–serving skew).
-
Reusability: Teams can share and reuse feature definitions across multiple ML projects.
-
Freshness: Supports both batch features (e.g., daily sales aggregates) and real-time features (e.g., number of clicks in the past minute).
-
Governance: Provides metadata, versioning, and access controls.
5. Training Pipeline
A training pipeline is a sequence of automated steps that takes features from either the Feature Store or directly from the Feature Engineering, fits a machine learning model, evaluates its performance, and stores the result in a Model Registry or artifact store.
In the animation about you can see where the Training Pipeline is placed with respect to other pipelines
Key steps in a training pipeline:
-
Data Ingestion → Pull features from Feature Store or directly from storage.
-
Splitting → Train/validation/test separation or time-based splitting.
-
Model Training → Training using algorithms (XGBoost, CatBoost, TensorFlow, PyTorch, etc.).
-
Hyperparameter Tuning → Grid search, random search, or Bayesian optimization.
-
Evaluation → Compute metrics such as accuracy, F1-score, RMSE, AUC.
-
Logging & Versioning → Store metrics, code, and artifacts in systems like MLflow or Weights & Biases.
6. Inference Pipeline
An inference pipeline is the path data takes from new inputs → feature transformation → trained model → prediction delivery.
Inference pipelines are tightly connected with data processing steps. That is why we typically have two types of Inference Pipelines.
-
Real-Time Inference: Serve predictions instantly via APIs (latency in milliseconds)
-
Batch Inference: Run predictions on datasets periodically (e.g., nightly)
Key steps in an Inference Pipeline:
-
Data Ingestion → Capture new data from APIs, streams, or batch jobs.
-
Feature Retrieval → Query the Feature Store for pre-computed features or compute on the fly.
-
Prediction → Load the model from Model Registry and generate predictions.
-
Post-Processing → Apply thresholds, business logic, or anomaly detection.
Postprocessed predictions are then stored on data storage as well as they can be directly served to an external business logic system.
7. Model Registry
A Model Registry is a centralized system for managing the full lifecycle of ML models. It ensures that models are tracked, governed, and promoted in a structured way from experimentation to deployment.
Model lets you:
-
Store models as versioned artifacts → Every trained model is stored along with metadata (hyperparameters, metrics, source code version, etc.).
-
Assign models to lifecycle stages → Manage deployment readiness with clear labels:
-
Staging → Candidate models that have passed offline evaluation and are under further testing (e.g., A/B testing, shadow deployment).
-
Production → The active model serving real traffic. There should usually be only one production model per use case.
-
Archived → Old or deprecated models no longer used but kept for traceability and auditing.
-

-
Promote and deploy the best-performing model → Transition models between stages after validation.
-
Roll back if needed → If a new model underperforms in production, revert to the previous stable version.
Tools commonly used:
-
Open-source: MLflow Model Registry, Comet
Here's how Model Registry fits the overall ML Solution Architecture. Compare this diagram with the diagram in the introduction to get a better idea of how it all comes together.
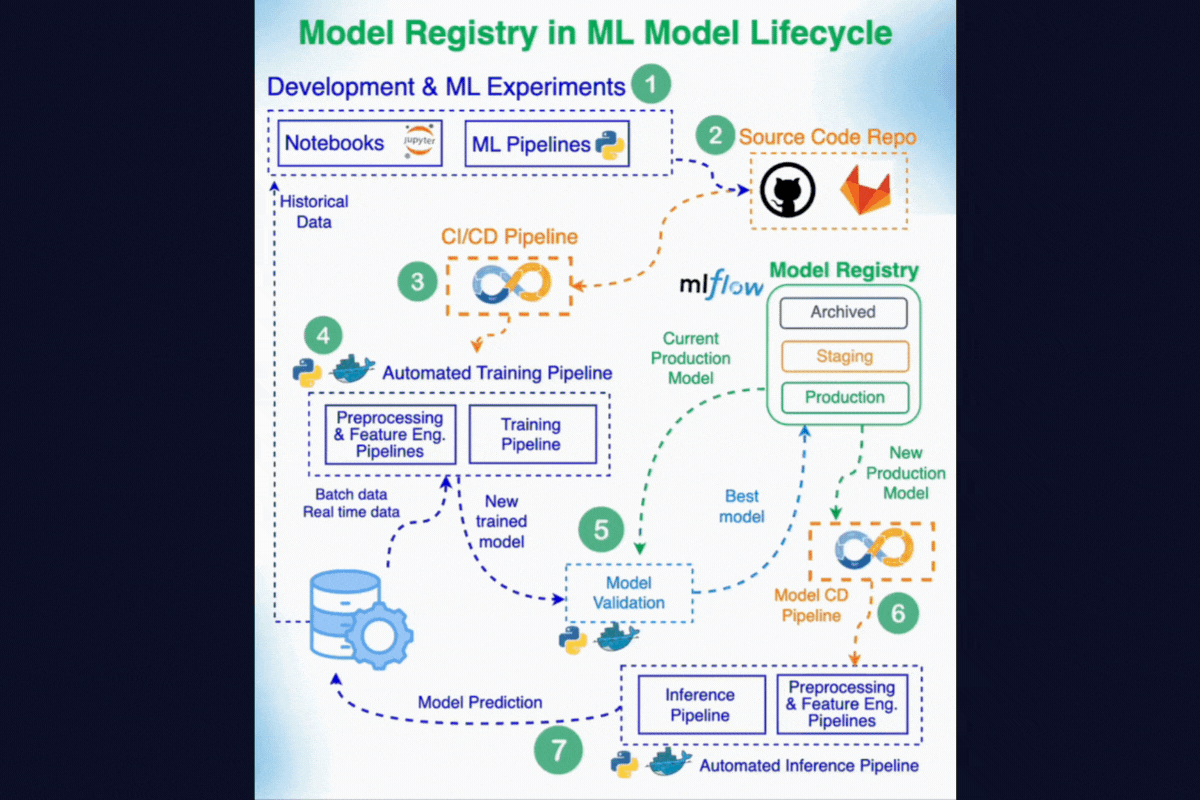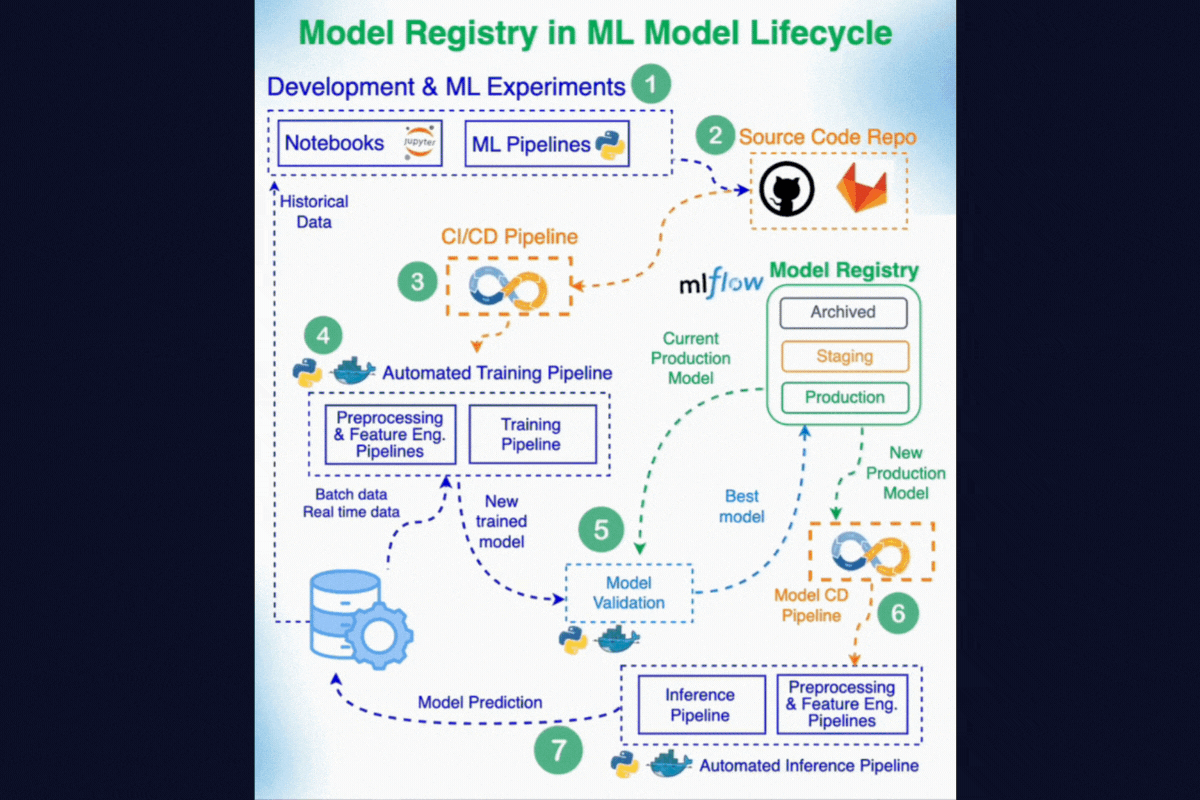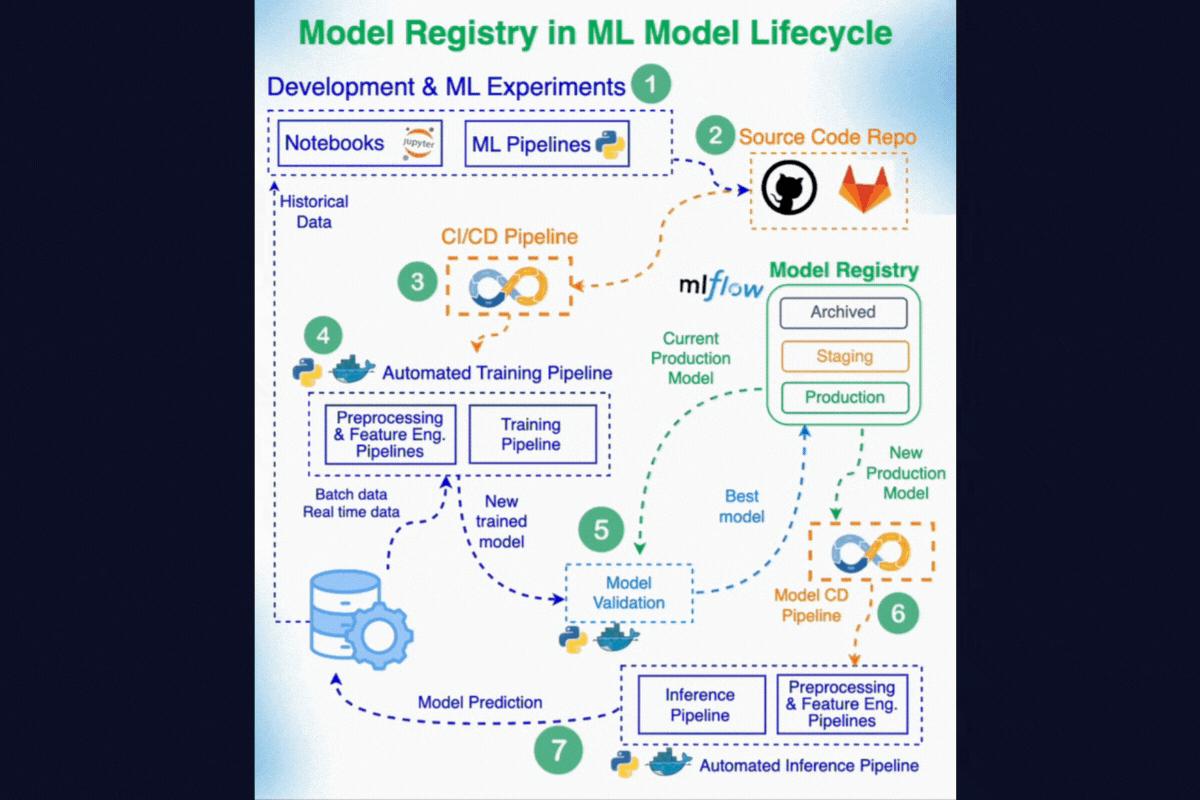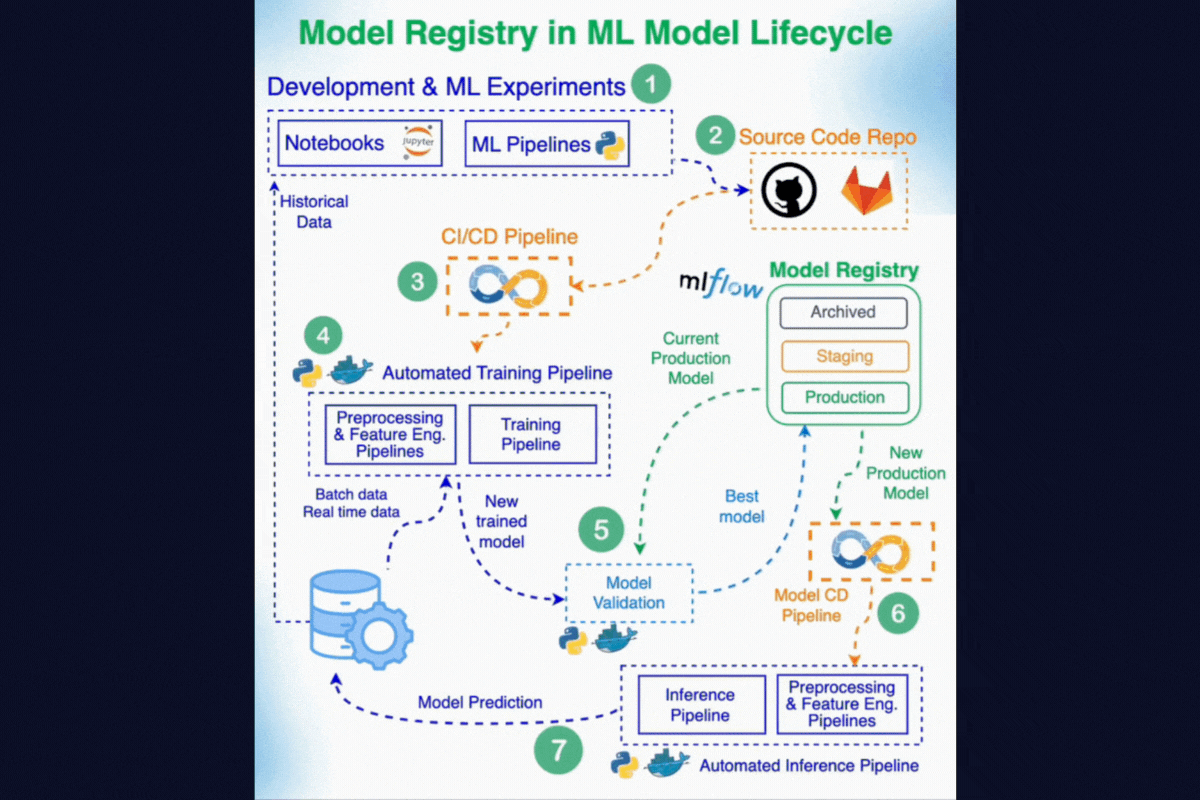
8. Experiment Tracking
Experiment Tracking is the process of recording, organizing, and comparing different model training runs. In modern ML solutions, dozens or even hundreds of experiments are needed before a model is good enough for deployment. Without proper tracking, it quickly becomes impossible to know:
-
Which code, data, and hyperparameters produced a model
-
How model performance changed over time
-
Which experiment is truly the “best” candidate for promotion
Key capabilities of an Experiment Tracking system:
-
Run Logging → Capture metadata like hyperparameters, metrics, code version (Git SHA), dataset version, and environment.
-
Versioning → Ensure every run can be reproduced, even months later.
-
Comparison → Compare runs across multiple experiments (e.g., different learning rates or algorithms).
-
Collaboration → Allow teams to share results, dashboards, and insights.
-
Integration → Link directly with the Training Pipeline and Model Registry, so that the best experiment can be seamlessly promoted to staging/production.
Tools commonly used:
-
Open-source: MLflow Tracking, Sacred, Guild AI
In the animation below, you can see how ML Experiment Tracking is embedded into the entire ML Life Cycle and what the path of the model is through that.

Below you can see a schematic representation of how Experiment Tracking is used in team collaboration and how it's connected to the Model Registry.
![]()
9. Data and Model Monitoring
The deployment of a machine learning model is not the end of the journey but the beginning of its most critical phase — production monitoring. In real-world environments, the conditions under which the model was trained rarely remain stable. Customer behavior evolves, sensor hardware changes, seasonal effects occur, or entire market dynamics shift.
These factors create a phenomenon known as data drift and concept drift, where the statistical properties of inputs or their relationship to outputs change over time.
Here's an animation showing how Data and Model Performance Monitoring might detect model performance degradation.
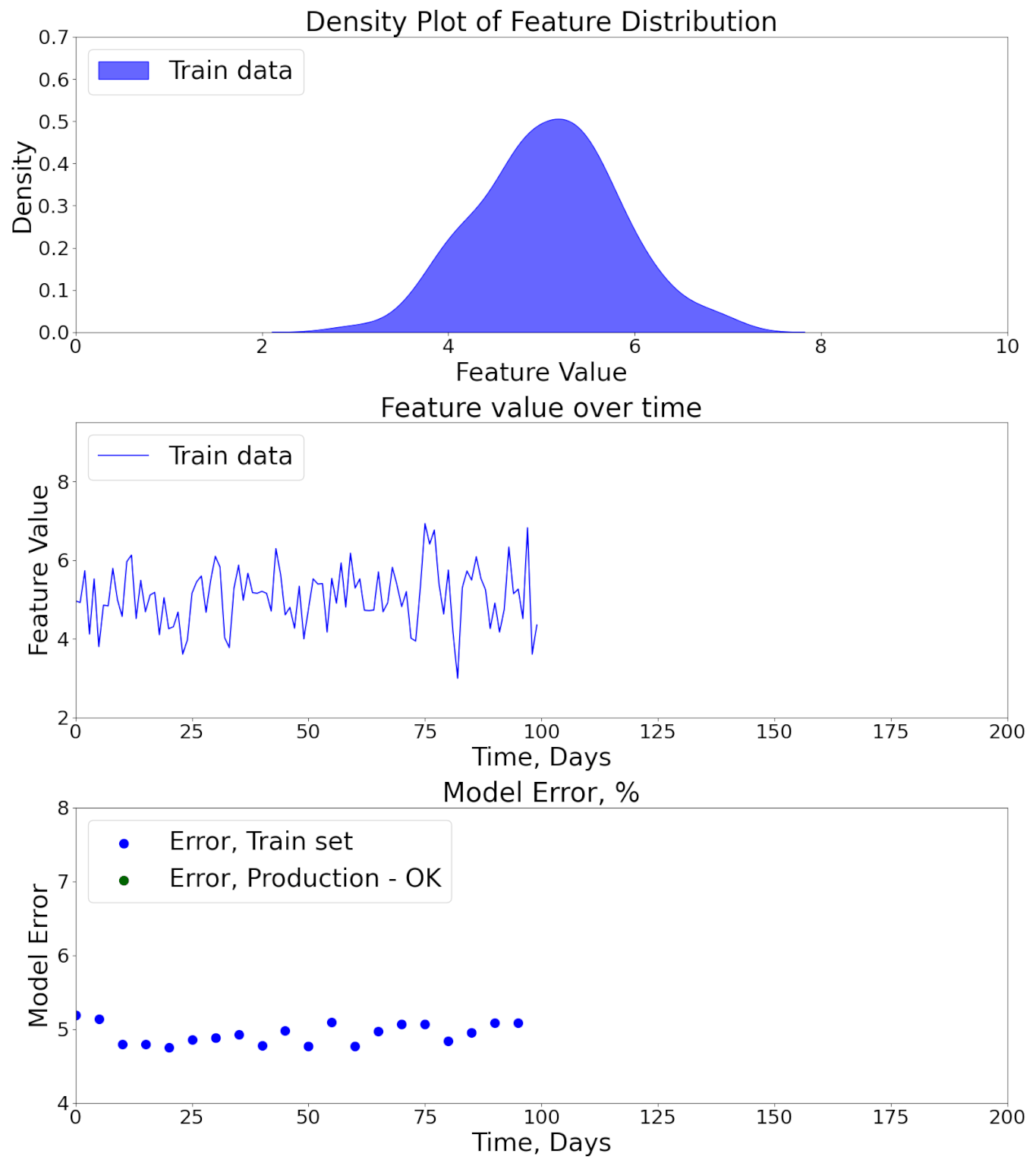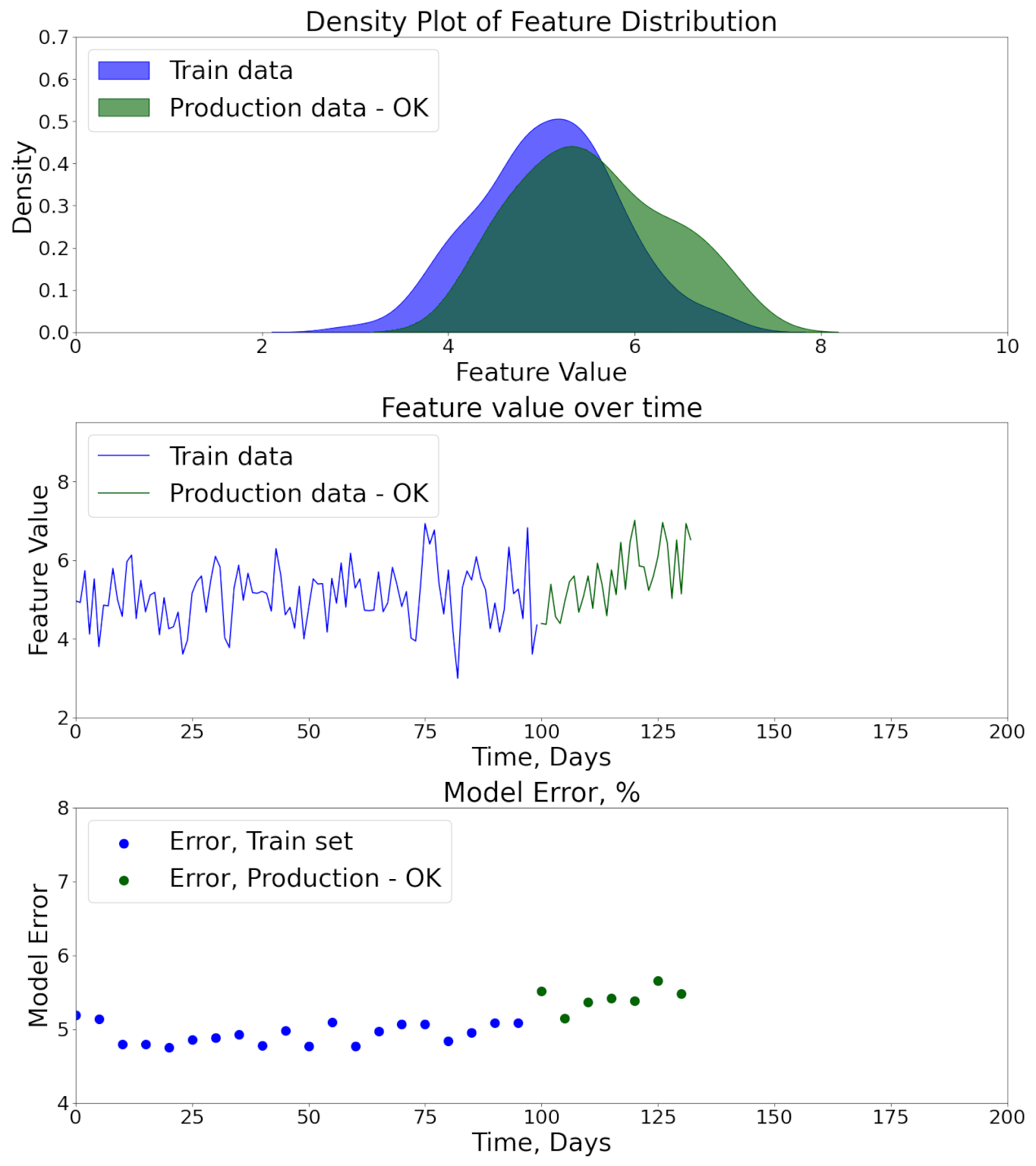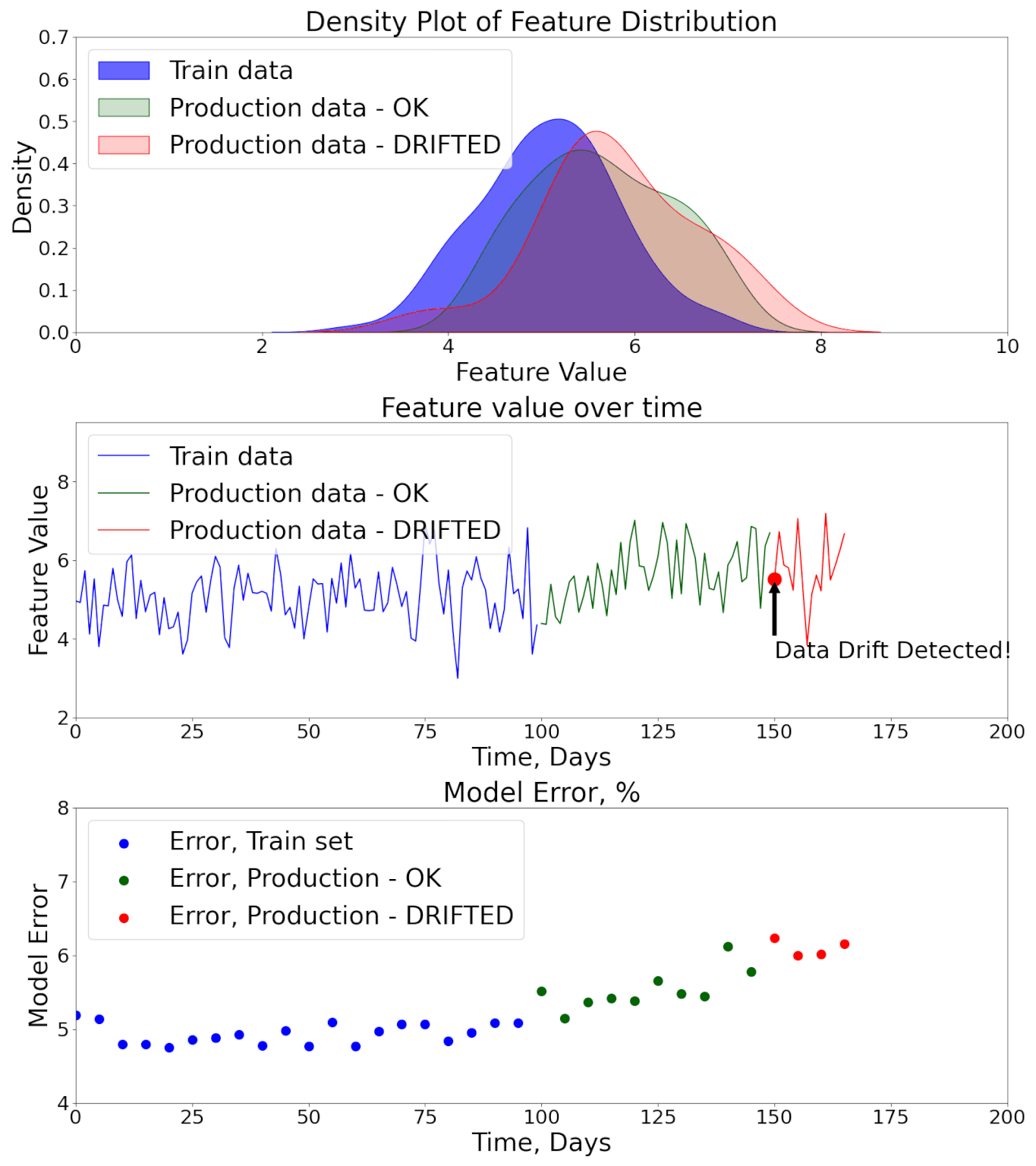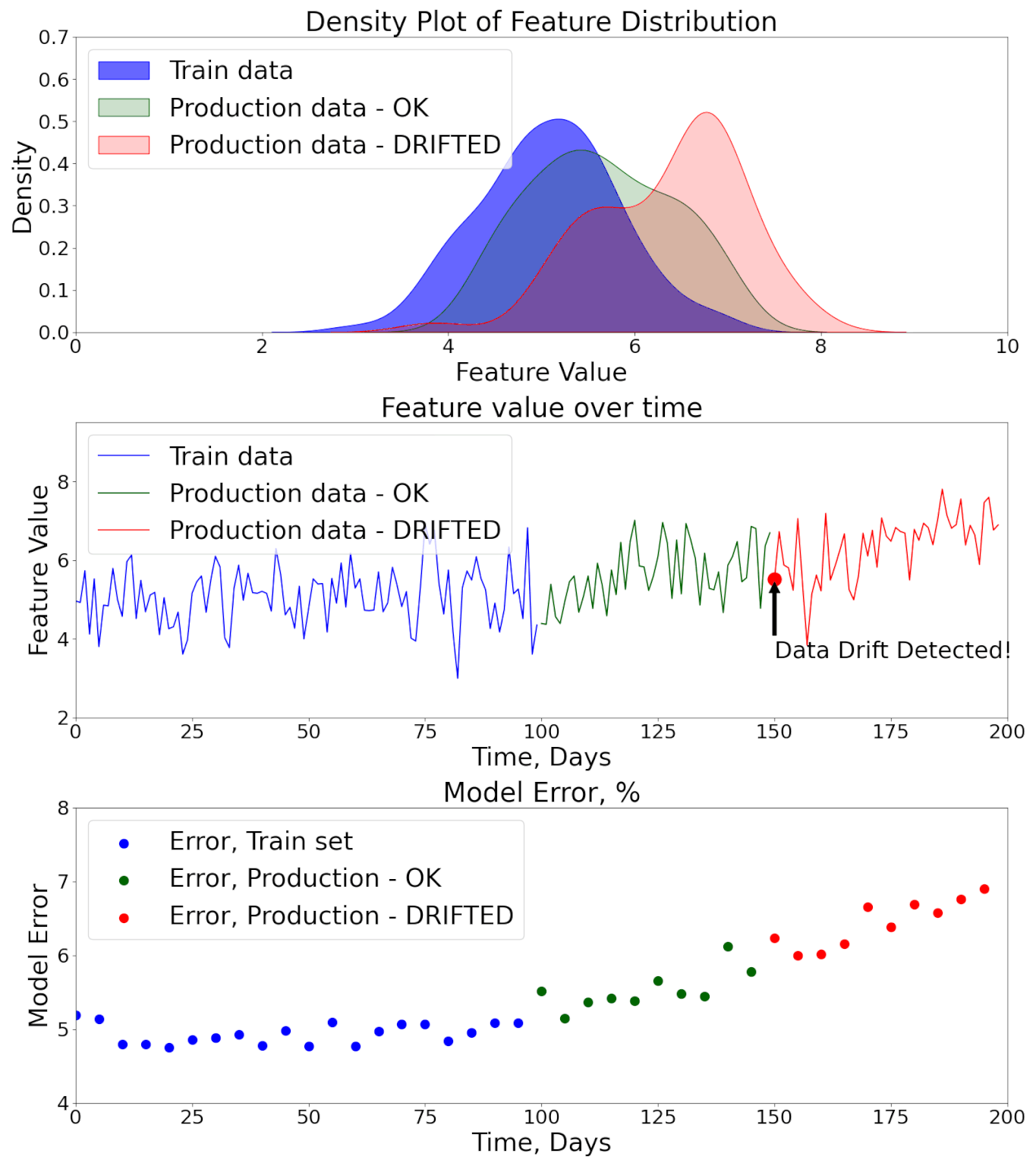
Without proper monitoring, models silently degrade, producing unreliable predictions that can directly harm business performance, user trust, or even safety. For instance:
-
A fraud detection system may become ineffective as fraudsters adapt their strategies.
-
A demand forecasting model may fail to capture sudden post-pandemic buying patterns.
-
A recommendation engine may reinforce stale preferences, missing emerging trends.
That’s why Model & Data Monitoring is a fundamental component of any production ML solution. It creates a feedback loop between deployed systems and the ML development lifecycle, enabling organizations to detect issues early, respond quickly, and maintain performance at scale.
What it covers:
-
Monitoring input data quality (missing values, schema changes, anomalies).
-
Detecting drift in feature distributions or target relationships.
-
Tracking live model performance against KPIs and business metrics.
-
Ensuring operational stability (latency, throughput, cost).
-
Alerting and triggering automated retraining when performance drops.
10. CI/CD for ML (MLOps Automation)
While monitoring ensures models stay reliable in production, Continuous Integration (CI) and Continuous Deployment (CD) ensure that every change — from data preprocessing scripts to model training code — can be tested, validated, and deployed quickly and safely.
In ML systems, CI/CD looks a bit different compared to traditional software engineering, because models are not just code, they’re also data-dependent artifacts. This means both data pipelines and models need to be versioned, tested, and deployed in a repeatable way.
Key aspects of CI/CD in ML:
-
Continuous Integration (CI):
-
Automates testing of preprocessing pipelines, feature transformations, and training scripts.
-
Validates data schema consistency and checks for data quality regressions.
-
Runs unit tests on ML code, integration tests on pipelines, and reproducibility checks.
-
-
Continuous Deployment (CD):
-
Automates the promotion of models from staging → production once performance and monitoring criteria are met.
-
Supports canary releases, shadow deployments, and A/B tests for safe rollout.
-
Ensures rollback to a previous model version is quick and reliable.
-
-
Continuous Training (CT): (often added in ML)
-
Automates retraining workflows when data or model monitoring detects drift.
-
Orchestrates pipelines to retrain, re-evaluate, and re-deploy models with minimal human intervention.
-
Why it matters:
Without CI/CD, ML teams spend weeks manually rebuilding environments, copying code, and hand-releasing models. With CI/CD, ML solutions become reproducible, scalable, and adaptive — the same qualities that make software engineering efficient now apply to machine learning.
Tools commonly used:
-
CI/CD pipelines: GitHub Actions, GitLab CI, Jenkins, CircleCI
-
ML-specific workflow orchestrators: Kubeflow Pipelines, MLflow, TFX
Best Practices for ML System Architecture
Start Simple, Scale Gradually
Begin with basic components and add complexity only as needed. Many successful ML systems started with simple batch processing and evolved into sophisticated real-time systems.
Prioritize Observability
Comprehensive monitoring and logging should be built into every component from the beginning. It's much harder to add observability after systems are deployed.
Design for Failure
ML systems will fail in unexpected ways. Design each component to handle failures gracefully and provide clear error messages and recovery procedures.
Automate Everything
Manual processes are error-prone and don't scale. Automate data validation, model training, testing, and deployment processes from the start.
Plan for Data Growth
Your data volume will grow faster than expected. Design storage and processing systems to handle 10x or 100x more data than you currently have.
Common Pitfalls and How to Avoid Them
Training-Serving Skew
When features are computed differently during training and inference, leading to performance degradation. Solve this by using feature stores and shared feature computation logic.
Data Leakage
When future information accidentally influences model training, creating unrealistically good performance that doesn't generalize. Implement rigorous temporal validation and point-in-time feature computation.
Model Drift Detection Delays
Waiting too long to detect model performance degradation. Implement real-time monitoring with appropriate alerting thresholds.
Inadequate Testing
ML systems require different types of testing than traditional software. Implement data validation tests, model performance tests, and integration tests specific to ML workflows.
Over-Engineering
Building complex systems before understanding actual requirements. Start with minimum viable architectures and evolve based on real usage patterns and requirements.
Conclusion
Building production-ready ML systems requires careful attention to architecture, component design, and operational practices. The 10 components outlined in this article form the foundation of robust ML solutions, but the specific implementation details will vary based on your use case, scale, and requirements.
The key to success is understanding that ML systems are fundamentally different from traditional software systems. They require new approaches to data management, model lifecycle management, and operational monitoring.
By following the architectural principles and best practices outlined in this guide, you can build ML systems that deliver reliable business value and adapt to changing conditions over time.
Remember that ML system architecture is an iterative process. Start with the basics, measure what matters, and evolve your architecture based on real-world experience and changing requirements.
The goal is not to build the most sophisticated system possible, but to build a system that reliably delivers business value while remaining maintainable and scalable.